Mapping Hidden Code Knowledge: Meta's AI-Driven Context Engine
Meta encountered a critical roadblock when deploying AI coding assistants on their complex data processing pipelines. The AI tools lacked awareness of the tacit knowledge embedded across four repositories, three languages, and over 4,100 files—knowledge that human engineers carried in their heads but was invisible to machines. To bridge this gap, Meta engineered a swarm of 50+ specialized AI agents that systematically parsed every file and distilled the tribal knowledge into 59 concise context files. The result: AI agents gained structured navigation guides for 100% of code modules, cutting unnecessary tool calls by 40%. This Q&A explains the problem, the innovative solution, and the outcomes.
What was the core problem with AI coding assistants at Meta?
Meta’s large-scale data pipelines are built on a config-as-code architecture combining Python configurations, C++ services, and Hack automation scripts across multiple repositories. When engineers tried to extend AI assistants to development tasks, the agents faltered because they lacked a map of the codebase. For instance, the AI didn’t know that two different configuration modes used distinct field names for the same operation—swapping them would silently produce wrong output. It also missed that dozens of deprecated enum values must never be removed because serialization compatibility depends on them. Without this context, agents would guess, explore, guess again, and often output code that compiled but was subtly incorrect. A single data field onboarding, for example, touched six subsystems (configuration registries, routing logic, DAG composition, validation rules, C++ code generation, and automation scripts) that all needed to stay synchronized. The AI had no understanding of these interconnections.

How did Meta solve the lack of context for AI agents?
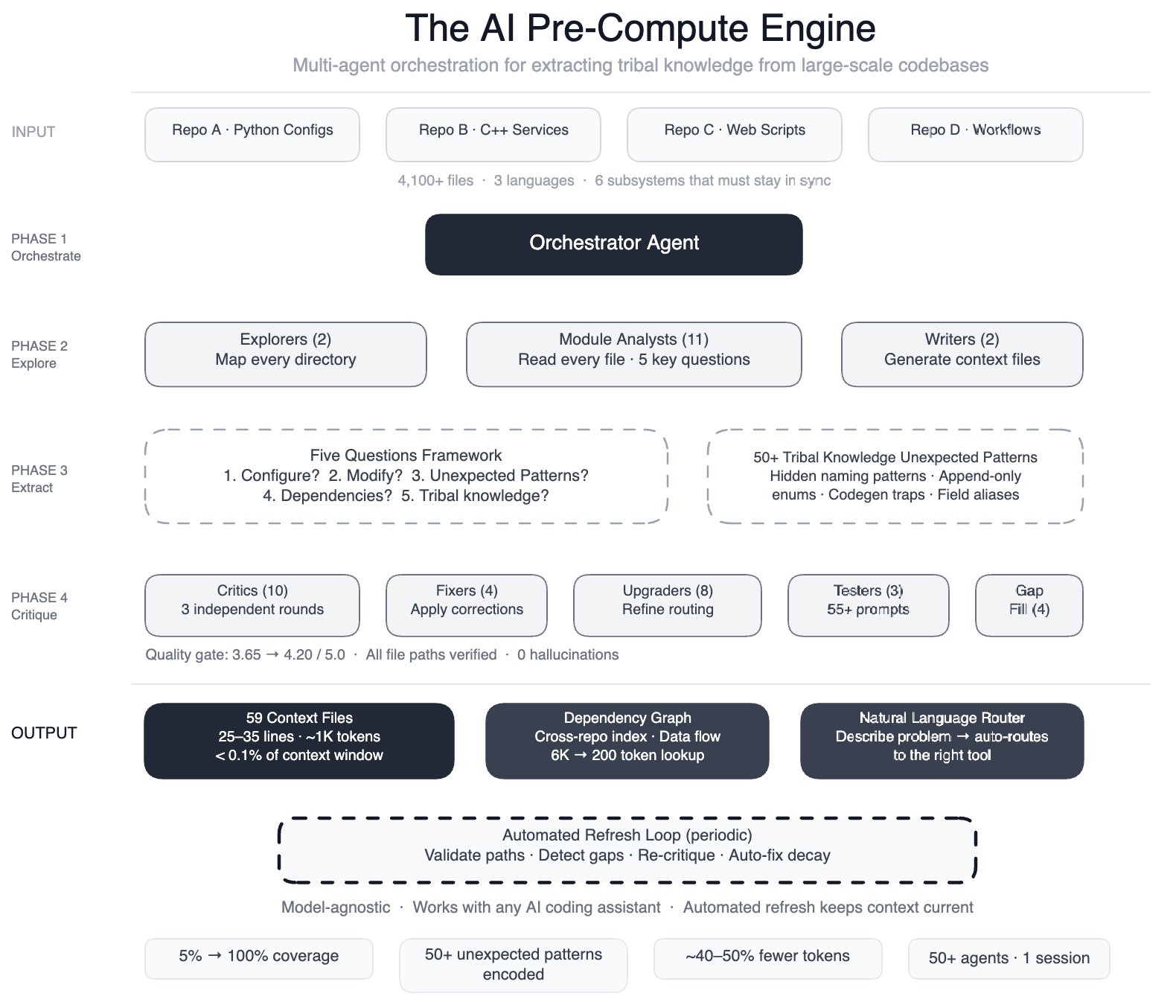
Meta built a pre-compute engine: a coordinated swarm of over 50 specialized AI agents that systematically read every file in the codebase. Instead of letting agents explore blindly, the team first created a knowledge layer that captured tribal knowledge. The engine operated in phases: two explorer agents mapped the codebase; 11 module analysts studied each file to answer five key questions; two writers generated context files; 10+ critic passes ran three rounds of independent quality reviews; four fixers applied corrections; eight upgraders refined the routing layer; three prompt testers validated 55+ queries across five personas; four gap-fillers tackled remaining directories; and three final critics ran integration tests. This orchestration produced 59 concise context files that served as structured navigation guides for AI agents, covering 100% of the code modules (up from 5% previously) across all 4,100+ files and three repositories.
What are the context files and what do they contain?
The 59 context files are concise documents that encode the tribal knowledge previously locked inside engineers’ minds. They include descriptions of each code module, its purpose, interfaces, and relationships to other components. Critically, they document over 50 non-obvious patterns—underlying design choices and interdependencies not immediately apparent from reading the code. For example, the files explain why certain configuration registers require particular field names, which deprecated enums must be preserved for backward compatibility, and how routing logic connects Python configs to C++ services. The knowledge layer is model-agnostic, meaning it works with most leading AI models because the context is stored separately from the assistant itself. This separation ensures the maps can be reused across different AI tooling.
What improvements were observed after implementing the context engine?
Preliminary tests showed a 40% reduction in AI agent tool calls per task. Fewer guesses and less exploration meant agents could make useful edits more quickly and accurately. The system now covers 100% of the code modules (over 4,100 files across three repositories) with structured guidance, compared to only 5% before. Human engineers also benefit: the context files themselves serve as living documentation that captures design rationale and implicit conventions. Additionally, the pre-compute engine is self-maintaining—automated jobs run every few weeks to validate file paths, detect coverage gaps, re-run quality critics, and auto-fix stale references. The AI isn’t just a consumer of this infrastructure; it’s the engine that keeps it running.
How does the system maintain itself over time?
The knowledge layer is designed for autonomous self-maintenance. Every few weeks, automated jobs perform a series of tasks: they validate that all file paths referenced in the context files still exist; they scan for newly added code modules that need context generation; they re-run quality critics to ensure the guidance remains accurate; and they auto-fix any stale or broken references. If a gap is detected—for instance, a new subdirectory added by developers—the system triggers additional explorer agents to produce the missing context files. This continuous validation ensures that the maps evolve with the codebase, reducing the burden on human engineers to keep documentation up to date. In effect, the AI becomes the caretaker of its own knowledge infrastructure.
Why is this approach model-agnostic and what does that mean?
The context files are stored as a separate knowledge layer, independent of any specific AI model. This means the same 59 files can be used with any leading AI assistant—whether it’s Meta’s internal models, GPT-4, Claude, or others—without modification. The knowledge layer provides structured navigation guides, non-obvious pattern documentation, and module descriptions that any model can ingest. This design avoids vendor lock-in and allows teams to upgrade or switch AI tools without rebuilding the mapping. It also enables parallel usage: different agents working on different tasks all draw from the same authoritative context, ensuring consistency across the pipeline. The team validated this by testing 55+ queries across five distinct personas (e.g., beginner engineer, expert reviewer, automation script), all of which benefited from the unified knowledge base.
Related Articles
- Python's Steep Learning Curve: New Findings Highlight Persistent Development Challenges
- Trump Targets Louisiana Incumbent: Endorses Julia Letlow to Oust 'Disloyal' Cassidy in GOP Primary
- Tame Messy Data: A Step-by-Step Guide to Cleaning Imported Spreadsheets with Power Query
- Navigating the Louisiana Republican Primary: A Guide to Trump's Challenge Against Sen. Bill Cassidy
- Google's New Storage Policy: Phone Number Required for 15GB Free Tier
- Google's New Storage Policy: 10 Crucial Changes You Need to Know
- Breaking: mssql-python Adds Native Apache Arrow Support for Zero-Copy Data Transfer
- 7 Reasons Pandas Still Reigns Supreme for Data Wrangling